DEFPプログラムとは
データアントレプレナーフェロープログラム(DEFP)とは?
概要
電気通信大学では、2015年度にデータサイエンス講座「データアントレプレナープログラム」を開講しました。以降、データサイエンスの実務に求められるスキルやマーケットの変化に対応するため、毎年カリキュラムを見直し、2017年度にはより実践的な内容を取り入れた「データアントレプレナーフェロープログラム」へと進化しました。『実学を学び、世の中を変える』という理念のもと、自らの力で課題を解決できる実践型データサイエンティストの育成を目指しています。本プログラムは、データサイエンティストとしての専門スキルに加え、ビジネス創出の視点を持ち、データを活用して新たな価値を生み出せる『データアントレプレナー』を育成します。具体的には、データ分析やモデル構築の技術だけでなく、課題発見から課題解決までのビジネス視点を兼ね備えた人材を輩出することを目指しています。

本プログラムのゴール
●データアントレプレナーフェロープログラム(前期コース/6ヶ月)
データサイエンスの基礎から応用までのスキルを習得し、データ分析者として独り立ちできるレベルに到達することを目標とします。
●データアントレプレナーフェロープログラム(通年コース/12ヶ月)
前期コースで習得したスキルに加え、高度な事例研究、提案力、実装力を身につけ、データサイエンスプロジェクトを推進できる総合力を養います。通年コース修了後に企業や研究機関で活躍できるエキスパートレベルのデータサイエンティストに到達することを目指します。
本プログラムの特徴
- 土曜日午後のフルオンライン授業を通じて、無理なく学び続けられる環境を提供
- 実務経験豊富な講師が、現場で役立つ技術や知識を指導
- グループワークを含む実践学習で、体系的に学びながら課題解決力を養成
本プログラムの対象
学生の方
- データサイエンスを学び、研究の幅を広げたい方
- 実践的なスキルを身につけ、就職活動を有利に進めたい方
その他
- データサイエンスに興味を持ち、新たに学びたいと考えている方
2026年度カリキュラム(予定)
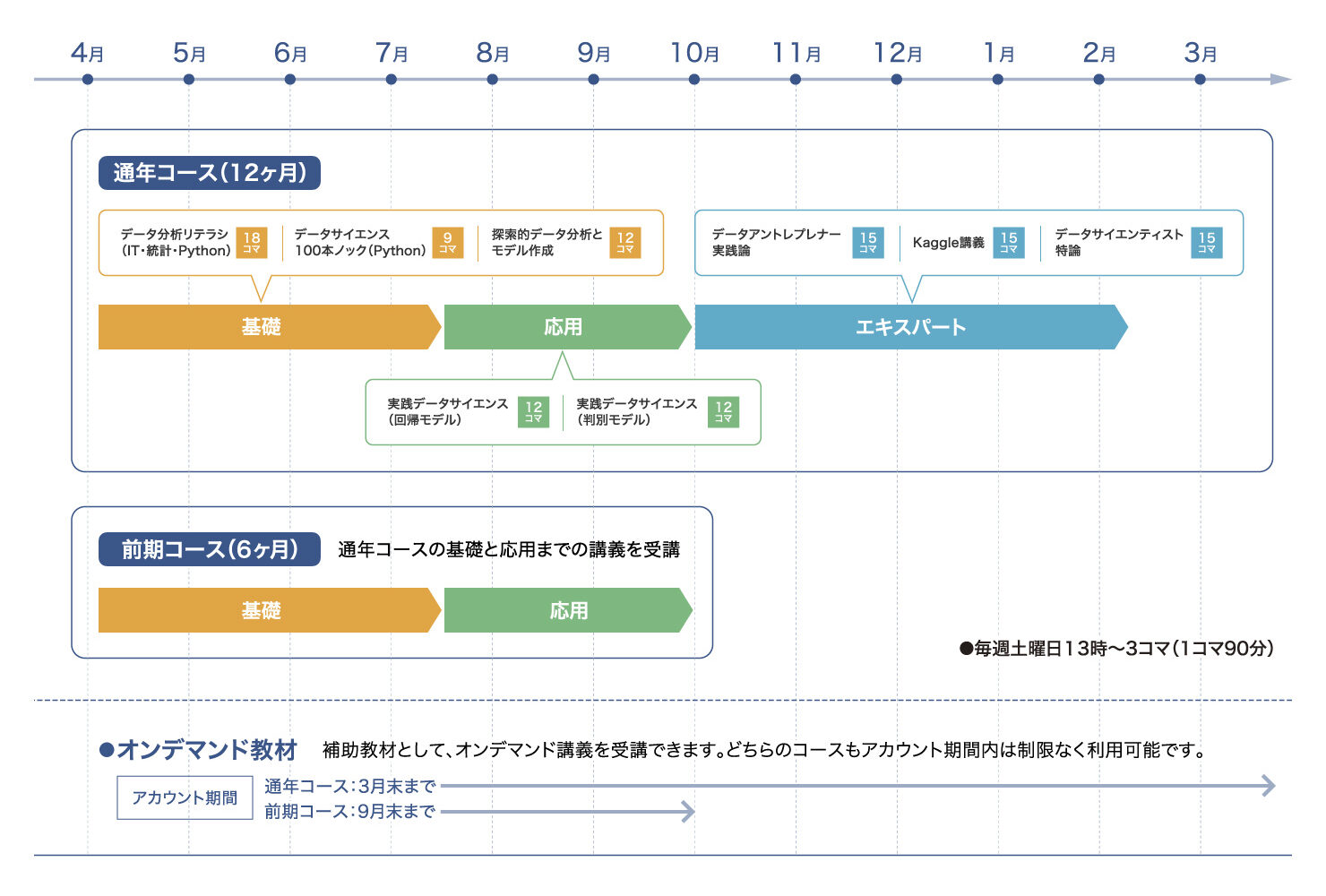
必修講義:基礎
zoomを利用したオンライン講義(ライブ配信)で行います。
データ分析リテラシ(ITリテラシ・統計・Python)
データを使って仕事をするための基本的なリテラシを身につけていただきます。
・ITリテラシ
- ssh通信を使ったリモート・サーバへのアクセス
- 文字コードと正規表現
- TCP/IPとhtml概論
- GitやGit Hubの利用
- SQL入門
・統計
- 確率・統計の中でリテラシとして身に着けてほしいものについて、事例を元に学びます。
・Python
- プログラミングが初めての方を想定したPython入門編となります。
データサイエンス100本ノック(Python)
一般社団法人データサイエンティスト協会が公開している「データサイエンス100本ノック(構造化データ加工編)」を活用して自習していただきます。質問等をSlackで受け付け、学習を進めます。
探索的データ分析とモデル作成
Pythonを使ってのデータの集計・可視化と機械学習の基礎を学びます。
- pandasによるデータ集計
- データの可視化とデータ構造
- モデルの精度と評価
- 判別モデル入門(titanicデータ)
- 回帰モデル入門(Jリーグ観客動員数予測)
必修講義:応用
zoomを利用したオンライン講義(ライブ配信)で行います。
実践データサイエンス(回帰モデル)
ワシントンDCの不動産物件価格予想問題に取り組む中で、回帰分析に必要な事項を基礎から学びます。グループに分かれて、モデルの精度を競います。講義のほか、実習が中心となります。
実践データサイエンス(判別モデル)
小売店舗における購買行動データを用いた二値分類問題(ある商品に関心を示す人/示さない人を予想する問題)に取り組む中で、回帰分析に必要な事項を基礎から学びます。グループに分かれて、モデルの精度を競います。講義のほか、実習が中心となります。本講義に使用するデータは、コンソーシアム参画機関であるコニカミノルタ株式会社が独自に取得したもので、マーケティングに直結する実用性の高いデータです。
必修講義:エキスパート
zoomを利用したオンライン講義(ライブ配信)で行います。
データアントレプレナー実践論
様々な分野の第一線の研究者、技術者、経営者から、データサイエンスを業務で扱うためのビジネス理論を中心に学習します。研究や実業での現実的な実例を学んだ後、受講生各人でデータサイエンスを使ったビジネス・プランを発表してもらいます。
2025年度:全15回(15コマ)
- 1. ガイダンス ― 国立大学法人電気通信大学 原田慧
- 2. データによる社会経済の可視化 ― 株式会社QUICK 北村慎也
- 3. データサイエンス/AI技術の社会実装の実際 ― 日本電気株式会社 デジタルテクノロジー開発研究所 相馬知也
- 4. データ解析によるビジネス意思決定 ― 株式会社D4cアカデミー 和田陽一郎
- 5. フリーランスや起業といったデータサイエンティストの多様な働き方について ― 株式会社Heliks Data 赤間悟
- 6.データアントレプレナー人財の育成について ― コニカミノルタ株式会社 清水隆史
- 7-9. 中間発表
- 10. Kaggleと現場におけるデータサイエンス ― パナソニック株式会社 阪田隆司
- 11. ロケーションビッグデータ分析事業の創業事例 ― 株式会社ナイトレイ 石川豊
- 12. 顧客価値を引き上げるアナリティクス ― 日本アイ・ビー・エム株式会社 西牧洋一郎
- 13-15. データから価値創造(ピッチコンテスト) ― 国立大学法人電気通信大学 原田慧
過去のカリキュラム
2024年度|2023年度|2022年度|2021年度|2020年度|2019年度|2018年度|2017年度|2016年度|2015年度
Kaggle講義
「データサイエンス」という言葉に比べれば機械学習モデルの構築は狭い領域ですが、モデル構築一つとっても、データを見て実際に処理してみないとわからないことが多く、教科書にならない独特のノウハウがあります。このようなノウハウの習得には、座学だけではなく、自分でデータを見て、自分でコードを書いた実践経験の積み重ねが不可欠です。Kaggleなどのコンペに参加することで、そのような職に就く前に擬似的な実践経験を積むことができます。ここでは各回、座学1コマ、演習2コマで、コンペ形式の演習を通して、モデル構築の技術を体得していただきます。
2025年度:Kaggle講義 全15回(15コマ)
- 1-3. 機械学習モデリング入門
- 4-6. 特徴量エンジニアリング
- 7-9. 時系列データ処理
- 10-12. レコメンデーション
- 13-15. マルチモーダルデータ処理
過去のカリキュラム
データサイエンティスト特論
データサイエンスの分析手法を実習で学びます。これまで学んできた様々な分析手法を、グループワークで、企業等に蓄積された実際のビッグデータに適用し、分析結果を出して発表します。最終結果は大学教員や企業でご活躍のデータサイエンティストの方々に審査されます。
過去のカリキュラム(データ提供企業と使用データ)
- 2024年度:コネヒト株式会社提供のアプリの検索履歴とQ&Aデータ
- 2023年度:株式会社ディー・エヌ・エーのゲームデータ
- 2022年度:逗子市の位置情報解析データ
- 2021年度:Jリーグ所属クラブ:鹿島アントラーズ、FC東京、川崎フロンターレ、名古屋グランパスのマーケティングデータ
- 2020年度:小田急電鉄株式会社の乗降客数データと小田急カードデータ
- 2019年度:株式会社ディー・エヌ・エーのモバイル・ゲームデータ
- 2018年度:不動産価格データ(オープン・データ)
- 2017年度:アスクル株式会社の売り上げデータ
- 2016年度:全日本食品株式会社のPOSデータ
- 2015年度:全9回(9コマ)
オンデマンド教材
補助教材として、オンデマンド講義を受講できます。どちらのコースもアカウント期間内(※)は制限なく利用可能です。
(※)アカウント期限 通年コース:3月末/前期コース:9月末
自然言語処理 基礎編
自然言語処理に取り組む上でのベースとなる、前処理についてご説明した後に応用篇のガイドを行います。スライド資料とノートブックによる演習を使って講義します。
自然言語処理 応用編
自然言語処理の発展的課題として、LDAによるトピックモデル、Word2Vec、BERTについて学びます。スライド資料とノートブックによる演習を使って講義します。
因果推論
講義資料を使って、因果推論についての基礎的な知識を学びます。
深層学習の基礎
進化のスピードの速いこの分野において、長く使える普遍的な考え方を身につけることを目的としています。講義資料と演習によって、理論的背景を数式からコードに書き起こすことで、理解を深めます。
レコメンドモデル作成
講義と演習教材によって、レコメンドモデルを作っていただきます。演習で使用するデータの多くはオープンデーターですが、一部、企業様からご提供のデータを使用いたします。
教師なし学習の基礎と演習
本講座では、EDAと教師あり学習に加えて、分析の幅を広げるうえで有効な「教師なし学習」を扱います。項目としては、クラスタリング、次元圧縮、埋め込み、異常検知の各種手法の紹介と、現場での教師なし学習の適用を想定した演習問題を扱います。